나무위키 최근 변경 사이트인 "https://namu.wiki/RecentChanges"를 크롤링 해 보자.

크롤링을 진행하기에 앞서 필요한 라이브러리 설치.
request 모듈 : python에서 HTTP 요청을 보내는 모듈
BeautifulSoup 모듈 : 웹페이지 HTML 문서를 파싱하기 위한 모듈(모듈명은 bs4)
anaconda prompt창(관리자 권한으로 실행)에 - pip install requests beautifulsoup4 lxml 을 입력해 라이브러리 설치!
(pandas는 이미 설치 되어 있어서 하지 않았다.)
먼저 크롤링할 주소를 정의하고, requests 라이브러리에 있는 메소드인 get으로 parameter을 보낸 후,
content 속성을 이용해서 response data를 byte로 return 해준다.
req.text로 써도 되는데, text 속성은 response에서 리턴된 데이터를 문자열로 리턴한다.
text속성으로도 한 번 써 봐야겠다.

설명은 주석으로 적어 놨으니 간단하게 설명해보자면, find 메소드를 이용해서 CSS style의 selector을 지정해서 원하는 내용이 있는 태그들을 지정했다.

태그들이 무엇인지는 원하는 웹페이지에서 크롬이라면 오른쪽 상단에 있는 점 세개를 클릭해서 도구 더 보기-개발자 도구에서 보면 된다.

CSS 태그가 'td'인 table_rows에서 'a' 태그인 것도 찾아서 page_url에 리스트 형식으로 넣어줌으로서 크롤링할 페이지 리스트를 생성한다.
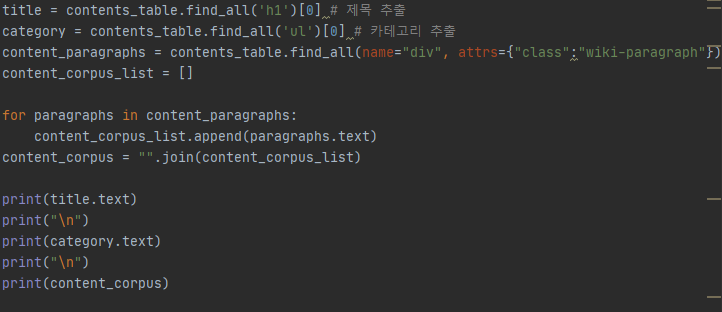

위에서 contents_table = soup.find(name="table") 이었다.
이 코드에서 title 은 contents_table에서 0번째(첫번째) h1을 찾는 거니까 첫번째 기사의 제목을 추출하는 것을 의미한다.
마찬가지로 category는 contents_table에서 첫번째 ul을 찾는 거니까 첫번째 기사의 카테고리를 추출하는 것을 의미한다.
(python 지식ㅜㅡㅜ) "".join(content_corpus_list) 의미는 list로 되어 있던 것을 문자열로 바꿔주는 것.

크롤링한 데이터들을 데이터 프레임(Data Frame)로 만들기 위한 코드이다.
첫 줄은 이렇고, 웹 크롤링 공부 첫 날은 여기까지 했다.
방학 때 공부하는 게 이렇게 힘들다니ㅜㅡㅜ
의지박약인 거 알긴 알았지만 이렇게 의지가 없을 줄이야..
뭘 공부해야 될 지 막막했었는데, 지난 학기 인공지능 수업 텀프로젝트인지 뭔지 했을 때 웹 크롤링을 이용해서 데이터 수집을 했다길래 궁금해서 공부 시작해봤는데 나름 재밌는 거 같다.
일단 시작했으니까 제발 제에에에에발 이 강의 끝까지 완료했으면 좋겠다!!
현재 듣고 있는 강의는 https://www.youtube.com/watch?v=cPhUKnLGoGw&t=634s 여기!
'프로그래밍 > 웹크롤링 & 텍스트마이닝' 카테고리의 다른 글
| [파이썬 웹크롤링] 인스타그램 크롤링 & 이미지 다운로드 받기 - 1 (0) | 2020.08.24 |
|---|---|
| [파이썬 웹크롤링] 파이썬으로 네이버 영화 댓글 데이터 분석 해 보기 (0) | 2020.08.22 |
| [파이썬 웹크롤링] 웹크롤링&텍스트마이닝 2일차 (0) | 2020.08.12 |